
Experiment I: Shifting Env
This page covers the first full experiment using the softmax actor-critic agent
Overview
For this simulated experiment, I took a new light scan in more direct sunlight. This significantly increased the power values as well as created more distinct optimal states to be in.
When I was initially developing the agent, I used a static environment where the reward array wasn’t shifting with steps. The Q-learning agent had some difficulty converging here, whereas the softmax actor-critic quickly finds and stays at the optimal state.

For context, the epsilon-greedy Q-learning agent would take closer to 20k steps to approach optimum in this experiment.
With the agent finding the optimal state in a static environment, I could now move on to a more realistic environment: one where the values are shifting with time throughout a day.
Environment Design
The general process for creating the environment in this experiment is very similar to the one outlined on Experiment Design with the exception of the third step:
Create a light scan using the solar panel
Convert that to a 2D reward array
Every N steps, shift the environment reward array by 1 in the x and y direction using np.roll
Here’s how this looks at each phase of the process:

1. Collecting the light scan
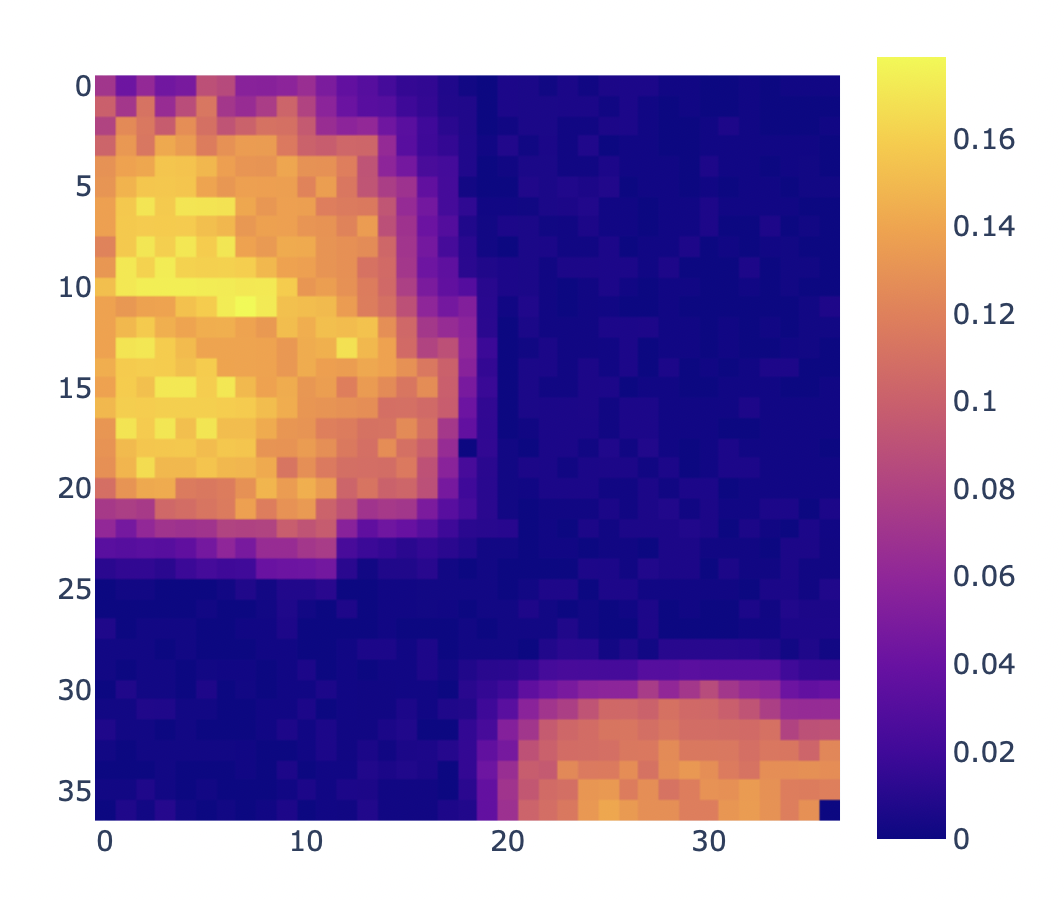
2. Reward array for environment
Agent Performance
Overall, the agent (softmax actor-critic) did not perform as I had expected in this experiment. While the agent successfully finds a near-optimal state prior to the environment shifting, it really struggles to adapt to the changing environment. Let’s look at a time series for the following scenario:
100,000 steps in the experiment
1,000 step environment shift frequency

The agent quickly finds a near optimal value before the environment shifts, yet at each ensuing shift, the agent does not appear to be locating the optimal state. Rather, the cyclic behavior in reward (red) can be explained by the agent staying in the same states while the environment rolls back around and eventually hits its original location
There are 37 indices in the env reward array, which means it will take 37 shifts to return to the initial position. The peaks are just about 37,000 steps apart (due to our 1,000 step shift frequency)
Hyperparameter Tuning
This agent was evaluated using an extensive hyperparameter search of over 10,000 combinations across actor step size, critic step size, temperature, and avg reward step size. What I noticed in the hyperparameter study is that the critic seems to have almost no effect on agent learning.

Example from more abbreviated hyperparameter study sweeping from 1e-4 to 1
So if no hyperparameter combo is delivering optimal performance, what’s going on with the learning algorithm? Shouldn’t the critic be having a meaningful contribution? If we dial up the logging granularity from 100 steps to 10 steps and look at a subset of the experiment (where the env shifts and reward is no longer high in the current state), we see some interesting delta behavior:

Delta (orange) flattens out
Why does this happen? Our actor’s probability values have been significantly blown out for the state that its settled on in the first 1,000 steps. When the state value decreases and the avg reward lags, the comparative delta on the negative side is so small compared to the probability values that have accrued that its hard to drive the probability values down. Thus, the agent remains in the same state.
How about the critic? Well, the agent keeps requesting the same state, so the critic’s comparison of current state value minus last state value is 0, which is why the critic has almost no effect on agent performance here.
Let’s look at how the agent’s state visits change as the experiment progresses:
The agent explores many states the first few hundred steps, then “permanently” settles on two states. I see this behavior happen for:
many different avg reward step sizes
many different actor step sizes
many different critic sizes
So, what’s the fix / what should be done to correct agent performance here?
Improving the Agent
I wrestled with the question above for weeks, and then it finally occurred to me: this is desired RL behavior, I’m simply not giving the agent enough information.
RL agents are faced with some new task, and for a given environment state, learn some optimal behavior to take
Without our agent having any indication of environment state (i.e., that it regularly shifts), we’re essentially having it learn something then totally shifting the dynamics of what it just learned seemingly at random and expecting it to re-learn on its own just for us to shift that all again
There is a distinction between what is happening above and non stationary environments. If we truly wanted our agent to have to continuously adjust to randomly shifting environments, we would design our agent differently.
In the context of our solar problem, we’re mimicking the movement of light throughout the day which is periodic due to time of day and seasonality
The Solution: Add some “time of day”-like metric to the input state feature (in addition to motor positions) so the agent can learn distinct behavior for each shift that is occurring. This lets the RL learn optimal positioning (on its own) for each time of day (env shift), which is more on the lines of what we can expect for an RL agent.
The shifting environment experiment has been a stark reminder about problem formulation in RL, and I’m excited to study the agent performance with the enhanced state feature.